The objective of this article is to understand the AI ecosystem. The series of articles to follow will explore the role each part of the ecosystem plays. This helps increase the adoption of AI in a way that boosts human productivity. In this series of articles, we will talk about various components of AI including:
Generative AI models
AI Infrastructure and Hardware
Security in AI
Ethical consideration and Governance in AI
Pricing models and how to estimate cost
Industry use cases for various verticals
Foundation Models
One term that we often use alongside Generative AI is foundation model. Foundation models, as the name suggests, act as the foundation of generating any content with AI. Foundation models are overarching models created on a huge dataset that can respond to a bunch of varying tasks. Think of a foundation model as a swiss army knife:
Versatile: The model is capable of handling wide range of tasks like text generation, image generation, translation etc
Adaptable: Model can be further fine tuned to suit a specific task with additional training data. A foundation model can be picked up by a large company and then further trained only on their internal data to become official company AI system for generating text.
Broad knowledge base: The model is trained on massive datasets ranging from different fields, giving it an overall idea and understanding of the world and various tasks expected of it.
A foundation model like GPT-4 can be used for various tasks like content generation, translation, summarization, code generation etc.
Large Language Models
An LLM on the other hand is a model trained for a specific purpose or task with the following attributes:
Specialized: Focused on human like text tasks such as language understanding and responses or generative content in texts.
Deep understanding: an LLM is trained on massive text datasets, it excels at text related tasks like creating content, analyzing grammar or sentiment of texts etc
Specific output: LLM can generate contextually relevant text which is highly nuanced as per the field it has been asked in.
An example of this could be an LLM which is specifically trained on medical data and literature, and is used by doctors for medical diagnosis and research.
It is common to find models which are both LLM and foundation models like GPT, Qwen and Llama.
Other than LLM, there are other specialized models on top of foundation models which handle tasks related to images, code, audio etc. Lets take example of Qwen which is an open source model developed by Alibaba and see its ecosystem:
Qwen is a series of LLMs developed by Alibaba Cloud. It has a foundation model Qwen-2.5 which is well trained for many generic tasks like text generation and completion, while there are many specialized LLMs focused on conversational AI, multimodal models etc.

Qwen 2.5: This ChatGPT like model is the general LLM which is trained on wide variety of datasets and is used for text generation, completion, answering questions, text evaluation and all the common tasks that we usually go to GenAI for.
Common general LLM models are ChatGPT (OpenAI), Gemini and PaLM 2 (Google), Llama (Meta) and Claude (Anthropic)
Qwen2-VL: VL stands for Vision-Language which means Qwen2-VL is a mutimodal model which can understand both images and texts. This model can be used to:
- Analyze images and extract information like identifying objects.
- Image captioning by generating textual description of the image and answering questions about the image
- Text to image creation
- Multimodal conversation which includes both images and texts
Other popular multimodal models are Gemini (Google), GPT4 with Vision (OpenAI), Flamingo (Deepmind) and LLaVA.
Qwen2-Audio: This is the audio based multimodal model which can work with both audio and text. Models like these can be used to:
- Create audio files
- Voice chat and conversational AI
- Audio analysis like speaker identification, translation, noise detection etc
- Multilingual support
Other popular audio models are Whisper (OpenAI), AudioLM (Google), Vall-E and SpeechT5 (Microsoft)
Qwen2.5-Coder: This LLM is designed with specific focus on code related tasks like:
- Code generation: Qwen2.5-Coder excels in generating code in various programming languages based on natural text like description (Eg: give me a code snippet for shopping cart page of an e-commerce app in java).
- Code understanding: The model can understand the meaning of the code, helping in working on someone else’s code, code debugging and code completion.
- Code Reasoning: The model can reason about code, helping developers improve performance of their code and help solve complex programming problems.
- Code fixing: The model can automatically detect errors in the code and fix them for developers.
Other popular coding LLMs are Codex (OpenAI), CodeGen (SalesForce), StarCoder (BigCode project) and AlphaCode (Deepmind).
Qwen2.5-Maths: This models is designed to tackle problems in the mathematical world. It is engineered to go beyond basic calculations and delve into the realm of mathematical reasoning and problem-solving.
- Mathematical Problem Solving: The model is trained to solve wide range of mathematical problems, from elementary arithmetic to complex calculus and algebra.
- Mathematical Reasoning: The model doesn’t just solve the problems but also demonstrates the reasoning process behind the solution.
- Tool integration: Qwen2.5-Math can be integrated with many tools like calculators and computer algebra systems to increase its application and accuracy of the solution.
Other popular mathematical models are Minerva and PAL(Google), Toolformer (Meta) and MathGPT.
Models are good, but what is 0.5B, 1.5B, 7B, 72B mentioned in the Qwen ecosystem image above?
The number we see as suffix in model names describe the number of parameters that the model has. The number of parameters in a large language model (LLM) is a crucial factor that significantly influences its capabilities and characteristics. Here, more number of parameters generally means a better model. The alphabet ‘B’ refers to billions so a model with 72B has 72 billion parameters.
Better capacity: Model with higher number of parameters have higher capacity to learn. Think of a library, a bigger library has capacity to keep more books which means it can contain more information than a smaller library.
Better Performance: Generally models with higher number of parameters perform better on variety of tasks like text generation, text analysis, translation etc.
on the flip side….
Diminishing returns: Increasing the number of parameters doesn’t always lead to a proportional increase in performance. At some point, the gains become smaller, and the cost of training and running the model becomes very high.
Parameters and Data mismatch: A model with too few parameters and large training dataset may struggle to understand the complexity of the data completely and may result in poor performance. On the other hand, a model with high number of parameters but limited dataset may end up overfitting the data which means that it memorizes the training examples instead of learning patterns, leading to poor performance with new data.
Cost of training: Models with larger number of parameters take more time and computational resources to be trained on new data. This leads to increase in total cost of training which needs to be balanced with the requirement from the model.
Where can you get these models for deploying
Just like the Githubs and Gitlabs of the world, there is a healthy ecosystem of repositories where most of these LLMs can be found. You can download the model code there and deploy for your personal or professional use.
Model Hubs and Repositories
Hugging Face: This is sort of the Github of the model world, and is the go-to platform for many open source LLMs. You’ll find models like LLaMA, various sizes of Qwen, and many fine-tuned variants.
ModelScope: Developed by Alibaba Cloud, this platform hosts theirs and many other models, including the Qwen series. It provides resources and tools for using and deploying these models.

Cloud Platforms
Amazon Sagemaker: AWS provides various ways to deploy LLMs. They also offer Amazon Bedrock which provides access to foundation models from different providers.
Google Cloud Vertex AI: GCP offers Vertex AI, which provides tools for deploying and managing LLMs. They also offer access to their own models, like PaLM 2 and Gemini.
Alibaba Cloud Model Studio: Alibaba offers access to various LLMs through ModelStudio. Apart from this, ModelStudio also provides end to end model development and deployment support including prompt engineering tools and knowledge base management
Microsoft Azure: Azure offers various AI services, including Azure Machine Learning, which can be used to deploy LLMs. They also partner with OpenAI to provide access to GPT models.
API Providers
You can also get access to various models through API providers like OpenAI API, Anthropic AI and Cohere.
Local Deployment
llama.cpp: This project allows you to run LLaMA models on consumer hardware, including CPUs.
Ollama: This tool simplifies running LLMs locally, including various Qwen models
Finally, how do I compare these models against each other
Comparing different LLM models can be a complex and sometimes subjective task. However, there are some common evaluation methods which use globally accepted benchmarks to define performance level of various LLM models.
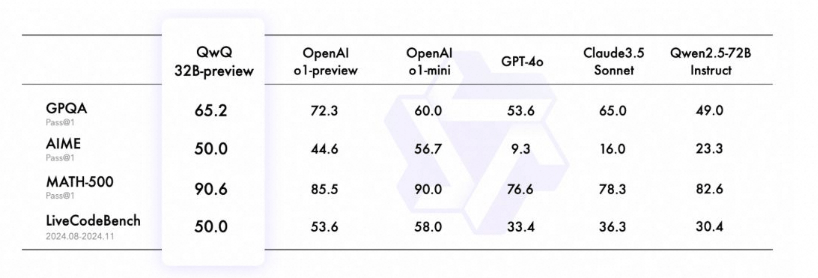
GPQA: GPQA stands for Graduate-Level Google-Proof Q&A. It’s a challenging benchmark designed to evaluate the ability of large language models (LLMs) to answer difficult questions that require deep domain expertise and cannot be easily answered by simply searching on Google.
AIME: The AIME stands for the American Invitational Mathematics Examination. It’s a challenging 15-question, 3-hour mathematics competition for high school students in the United States. AIME is often used to test performance of LLM models to see how they will perform in such a test.
MATH: MATH is a popular benchmark specifically designed to test mathematical problem-solving in LLMs. Its difficluty ranges from high school to early undergraduate level.
LiveCodeBench: LiveCodeBench is a recently introduced benchmark designed to evaluate the coding capabilities of Large Language Models (LLMs). It covers the shortcomings of previous code testing evaluation methods like HumanEval.
Below is the comparison of recent performances by latest version of popular LLMs like Qwen Qwq which is the latest (preview) reasoning model from Alibaba Qwen, Open AI o1 (preview), GPT-4, Claude3.5-Sonnet and Qwen2.5
Next blog to follow in the series: AI Infrastructure and Hardware
Cover Photo by Bernd 📷 Dittrich on Unsplash
