In 2002, the term web 2.0 emerged. It was a time of rapid evolution of web and how people interacted with it. Coupled with ever increasing internet speed, it also popularized a new way of talking to the internet – by sharing your own content. So far, the web meant passively interacting with websites that had information for you to consume. With emergence of blogging, people could now put their own content on internet and others could interact with them via comments and feedback. This was soon followed by social media websites like Orkut, Facebook and MySpace. All of this increased the total amount of data available on internet massively. A bigger explosion in this number came with Youtube, and now users could share media files in form of videos. The total amount of data being generated on internet was close to 300 exabytes by 2007. Companies loved to run analysis on their data to get some insights about the business and its users. But with such huge amount of data, analysis came with its own set of problems. And that is when the field of Big Data was born.
Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data processing systems (wiki). Today, everybody is talking about big data and any business which is generating huge amount of data wants to take advantage of big data solutions to understand their business better. And if we want to understand big data, we need to look at why was it required and how traditional solutions fell short. Let’s try to understand this using the example below:
John has opened a tailoring store where he would make customized shirts for his customers. As the venture is new, John receives only about 2-3 orders per day which he is able to deliver comfortably. He has created a raw materials room where he keeps all the fabric and other tools. He picks desired fabric from the room and works on the order.
This is a comparable situation for traditional data processing systems where the data was generated at a steady rate and was structured in nature. Therefore, the processing systems could comfortably manage analysis. All the data was stored in RDBMS and processing systems would import data from it.

With time, John created online presence for his company, John has now started getting 15-20 orders everyday. With the increased intensity of work, he was not able to complete all orders by himself. John decided to hire multiple tailors who would all make shirts. All these tailors would now be able to access the common raw materials room and work on their respective orders. This situation improved the performance but the raw materials room quickly became the bottleneck. Multiple tailors would argue over getting the same fabric, and sometimes one tailor would have to wait outside the room till the other finishes his work inside. This system did not work well when orders increased rapidly, even with a bigger raw materials room.
For traditional processing systems and RDBMS, performance will reduce with increased data and hence multiple processing units can be employed and data can be stored into a bigger centralized storage called Data Warehouse. All the processing units will get the analysis tasks, and they will access the data warehouse for getting the data. However, with ever increasing data and requirement for real time analysis, the centralized data warehouse will become a bottleneck as processes will fight for resources and data access.

Now, John has decided to break the shirt tailoring into smaller tasks of cloth cutting, collars, cuffs, button stitching etc and given these tasks to different tailors with 2 tailors taking each task. Now we have 2 tailors cutting fabric, 2 making cuffs, 2 making collars etc. He then would transfer all the pieces to another set of tailors who would stitch all the pieces together and finish the shirt preparation. All of these tailors have now been given their own mini raw materials room containing the same materials, due to which there is no loss of productivity over room sharing issues. In this scenario, John has also increased availability of workers as every task is given to two tailors. In case one of the tailors calls in sick, John would have one more tailor who can manage the same task. Same is the case with raw material rooms, as there are multiple rooms. If one of the rooms is not available due to some repair works going on, the tailors can pick up material from other room. In this framework, we have made the entire process parallel and distributed.

In data processing systems, we need a similar framework, and this is where Hadoop come in. Hadoop is a framework that allows us to store and process large datasets in parallel and distributed fashion. Let’s look at the two problems we have faced so far with increasing amount of data:
Storage
Like John solved the storage issue by distributing raw materials room among tailors, we also need data to be distributed. This is done by Hadoop File System, also known as HDFS. With HDFS, now the large amount of data is distributed among different machines where processes will run individually. These machines are interconnected and this group of machines is called a Hadoop cluster.

Parallel Processing
Like John divided the shirt making process into smaller tasks of making collars and cuffs, cutting fabric etc, Hadoop also divides the bigger analytics question into smaller tasks and run it on different machines in a hadoop cluster. This is called MapReduce. MapReduce allows parallel and distributed processing in a cluster, where smaller tasks similar to cutting fabric and making collar are run in a process called Map. Then, the result of these processes is combined just like second level tailors stitched all pieces together, and this process is called Reduce.
High Availability in Hadoop
High availability in Hadoop is maintained through Master Slave architecture. In a hadoop cluster, one node is a master node, and rest of the nodes are slave nodes. As the big problem gets reduced into smaller tasks, the slave nodes are given these tasks by the master node. The master node also gives backup tasks to nodes, which are primary task for some other node. This way if one node fails, there would be other nodes who will be able to perform that task. The master node keeps note of all this metadata.
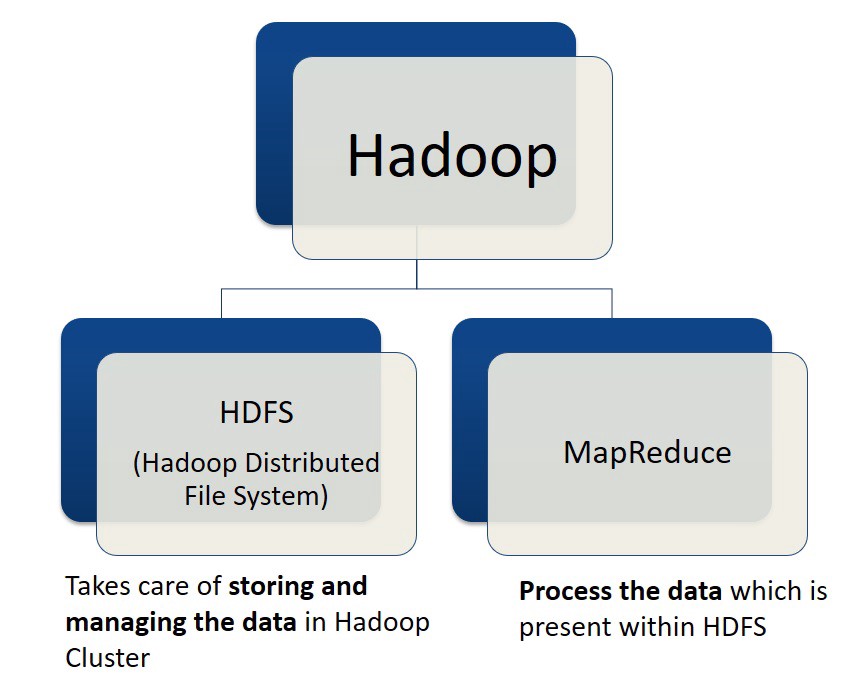
HDFS
In HDFS, there are three core components:
Name Node: The master node that maintains metadata about all the nodes.
Slave Nodes: The nodes that have actual data stored in them and communicate with name node via heartbeat signals that give information to the master node about health and uptime of the slave node.
Secondary Name node: The name node contains two files to store metadata: fsimage and editlog. fsImage file has the actual metadata and editlog has data about recent changes done in the system. The secondary name node maintains a copy of fsImage and editlog files and constantly adds the editlog content into fsImage file. This keeps the fsImage file updated and it also keeps the editlog file size small which is important as editlog file is stored in RAM of the machine. At every periodic event called checkpoint, the secondary name node replaces the fsImage file in the primary name node with its updated copy of the file. This keeps the fsImage file updated in the primary name node.

How does HDFS store files
HDFS divides the storage into smaller 128 MB blocks and each file is stored in these blocks. If the file size is 512 MB, it will be divided into four parts of 128 MB each and these four parts will be stored in four data blocks. These data blocks will be distributed to data nodes in the hadoop cluster. To ensure fault tolerance, a data block is distributed to at least 3 different data nodes to ensure data is persisted in case of a node failure. When the client would want to write data into a particular data block, it would raise a request to the name node. The name node will provide IP address of all the data nodes that have the particular block stored in them. The client will then use the IP addresses to locate the machines and update the required block.
MapReduce
Imagine a book publishing house where a 200 page book is ready to be published and the script needs to be proofread to find out errors. To save time and complete the task quickly, four employees at the publishing house divide fifty pages each among them and provide their respective total error count to the chief editor. The editor adds all these counts and comes to the final number of errors. This is MapReduce at work. The Map program is the division of task into smaller sets and distributing it to different processing units. These units’ respective output is then fed to Reduce program which collates these output and provides the final result.
A common example of MapReduce is the word count program. Input is given as a text paragraph and the program has to count how many times each word is repeated in the text. In the below example, the input contains sentences consisting of words like Lion, Tiger, River and Bus. We want to count the presence of each word in the paragraph. For this, first each sentence is split and provided to each processing unit. Each processing unit runs map code and maintains the count for each word in the sentence. Then, through shuffling all unique words are maintained in its own list. Finally, the reduce program adds all the numbers for a given word and gives the final output for all the words.

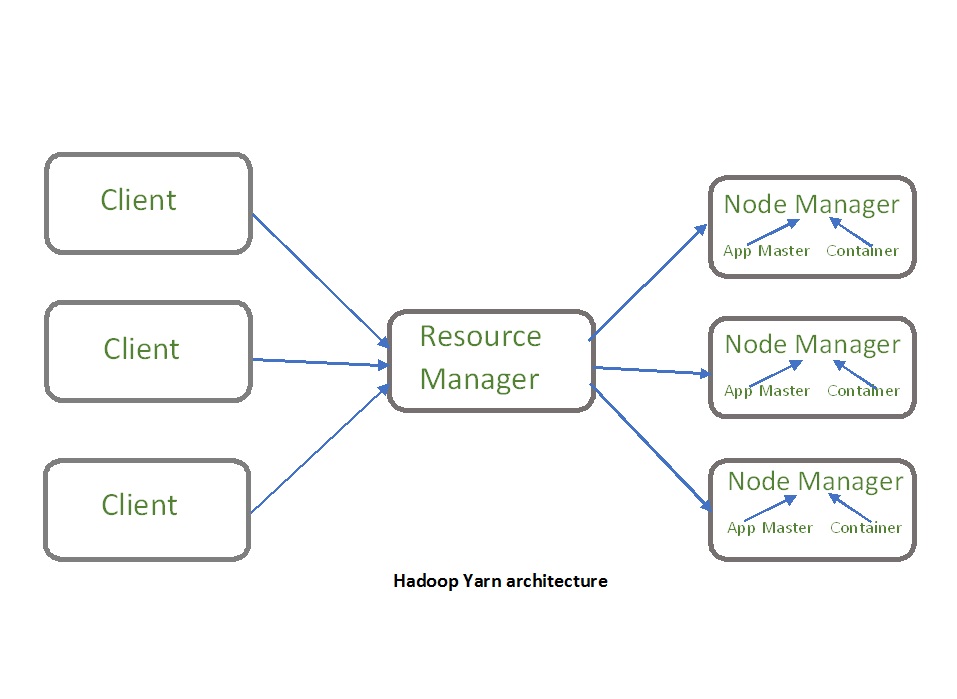
YARN
YARN stands for Yet Another Resource Negotiator, and is considered as next version of MapReduce. YARN has a master slave architecture where we have a Resource Manager node acting as the master and a Node Manager acting as slave. The node manager manages the App Master and the Container in the slave node. App Master is created when MapReduce job is provided to the Resource Manager. App master’s work is to monitor the MapReduce job and negotiate with Resource Manager for resources required for the job. The container is the actual unit of CPU and memory which is allotted for completing the job.
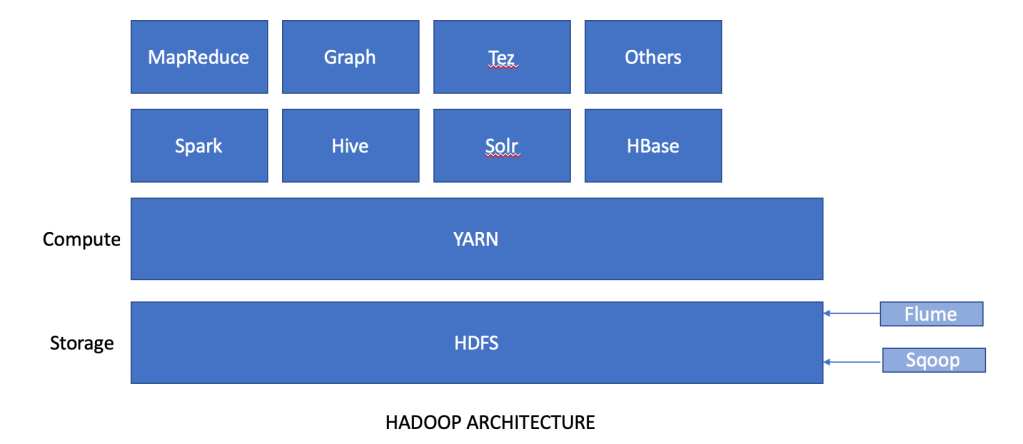
In short, YARN is the computational layer of Hadoop while HDFS is the storage layer of Hadoop.
Hadoop architecture: HDFS and YARN
Both HDFS and YARN follow the master slave architecture and handle the distributed storage and parallel processing respectively.
HDFS and YARN are the basic building blocks of the Hadoop Ecosystem which includes solutions like Spark, Hive, HBase, PIG etc which we will discuss in the next part.