In the first part of this blog entry, we looked at what big data is, and what are the main pillars of the solution – Hadoop, MapReduce and Yarn. These technologies form the basis of many big data solutions. Let’s look at these technologies and how are they used in the field of big data analytics.
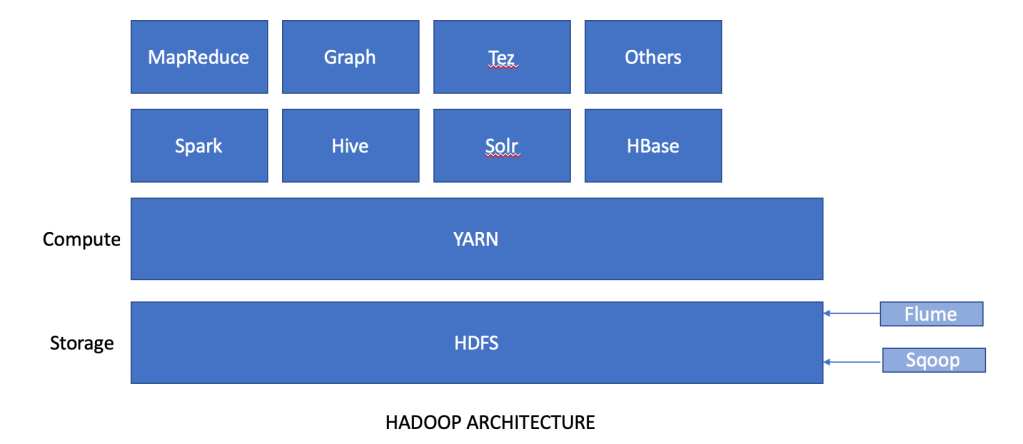
Ingestion
In order to start analysis on big data, the first step we need to ensure is to have data imported into HDFS storage. The data in question can be stored in traditional relational databases or in NoSQL databases. And this is where our two important ingestion tools come into picture.
Sqoop
Sqoop is an amalgamation of two words: SQL and Hadoop. By its name, it is easy to guess that it is an ingestion tool that works between relational database and HDFS. In absence of Sqoop, developers would have to write complex mapreduce jobs to import and export data from RDBMS to HDFS. Sqoop is a CLI based tool that makes it easy to transfer bulk data between RDBMS and HDFS. Internally, Sqoop converts the job into mapreduce task for import and export, but the user does not have to bear the complexity of it. Sqoop brings various features to the table like full and partial load, parallel import/export, compression of data during job, adding security while transfer etc, and this makes the ingestion process very simple to execute and manage.

Flume
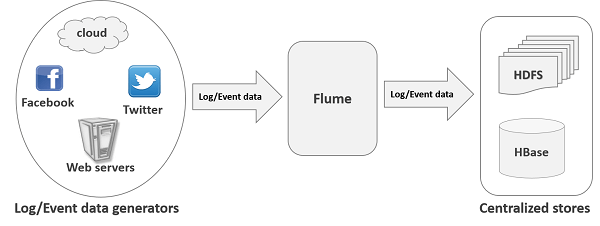
In the world of poly persistence, there are various types of data apart from relational data (eg: logs and events) and this is where flume comes in. Flume is a reliable and distributed service for systematically collecting, aggregating and moving large amount of streaming data into HDFS. In comparison to Sqoop which works with structured data, Flume works as a reliable ingestion tool for semi structured and unstructured data into HDFS. Common use case for Flume is collecting real time data from social media forums like twitter and facebook and ingesting into HDFS or Hbase using Flume.
Apache Pig
In MapReduce, users had to write programs in Java or Python in order to execute Hadoop tasks. This created a hindrance for many users who were not proficient in these programming languages. In order to overcome this, Yahoo introduced Pig which is a high level data flow system. Pig allows users to write simple queries in a language called Pig Latin, which are then internally converted into mapreduce programming to execute the task. Pig Latin is extremely efficient. It is estimated that 10 lines in Pig Latin is equivalent to approximately 200 lines of code in MapReduce. This drastically reduces the programming and development time and effort for HDFS tasks. In Apache Pig, there is inbuilt support for data operations like join, filter, sorting etc. Pig also gives you features of writing User Defined Functions (UDF) in languages like Java, Python, Ruby etc, and these UDFs will be executed in Pig Scripts that you write.
Pig consists of two components: Pig Latin, which is the language in which the queries are written; and Pig Execution, which guides the way how the Pig query will be executed. Pig queries can be executed in form of a script (.pig file), or in a grunt shell in an interactive manner, or the pig script can be provisioned in a java client application and get executed.

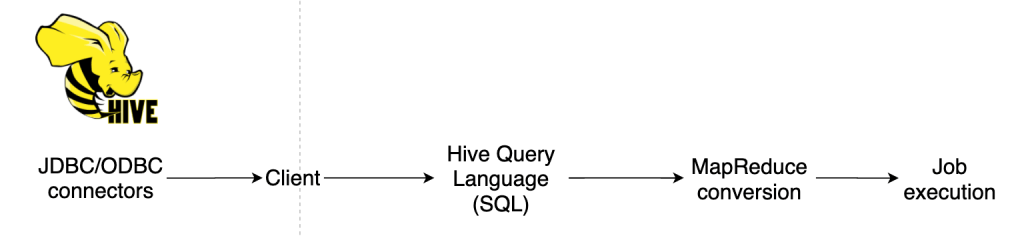
Apache Hive
Just like Pig, Hive also came into existence to overcome the skillset issue of having to deal with programming languages for writing mapreduce jobs. While Pig was developed by Yahoo, Hive was developed by Facebook. And Facebook built Hive in a manner which made working with Hadoop even simpler than with Pig. With Hive, users could now write the queries in existing SQL form, and Hive would translate that into mapreduce code which then would be executed. In this way, users did not have to learn a new language like Pig Latin, to write hadoop tasks. Most of the users in data teams are familiar with SQL and hence Hive quickly became a popular tool for hadoop users. The language used in Hive is called HiveQL and it is highly compatible with SQL. Hive works very well with structured data but has limitations with semi structured and unstructured data. Unlike pig, hive supports partitioning of tables and has JDBC/ODBC connectivity.
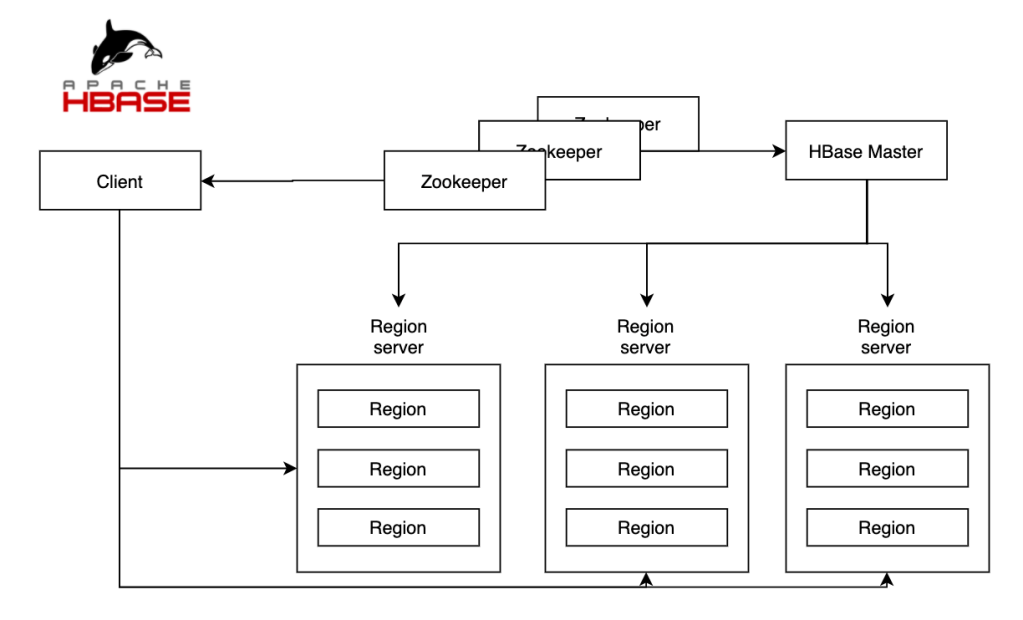
Apache HBase
HDFS stores and processes large amount of data efficiently. However, it performs only batch processing and data will be accessed in a sequential manner. This means that a user will have to insert the entire data set for even small tasks. Therefore, a solution is required to access, read and write data anytime irrespective of its sequence in the data cluster. Solution: HBase.
HBase is a NoSQL database solution built on top of HDFS and is classified as a key-value store. With freedom with schema related storage issues, HBase is a popular database for many organizations which generate tons of data in a very short amount of time. HBase is also a column based database which means that columns in the table are grouped together as column families. For eg: First name, middle name and last name columns can be part of the column family – Customer name. Column families are grouped together on the disk during storage and thus makes performance of the database faster when searching only on the relevant column families and ignoring other column families.
HBase works on the concept of master and slave architecture. HBase master nodes handle the responsibilities like creation and deletion of tables and handling the splitting of slave servers. The slave servers are grouped together into regions servers which have thousands of regions in it. A region can be defined as a group of rows in a table. There is another component called zookeeper which handles the syncronization between all these region servers and their coordination. All region servers and the HBase master regularly send heartbeat to the zookeeper which indicates which servers are active and healthy. This ensures high availability and unhealthy servers are replaced by the zookeeper.
Apache Spark
Big data processing can be broadly separated into two blocks: batch processing and stream processing. As the name suggests, in batch processing, batches of data are sent for processing in regular intervals, while in stream processing, there is a constant real time stream of data which is processed on the fly. Apache Spark is a very popular tool used today for stream processing and analytics. Spark is an in-memory, open source and parallel execution environment for analytics application. Much like MapReduce, spark also distributes the data into clusters and executes them in a parallel manner. The difference here is that unlike MapReduce, Spark manages the processing in-memory and this makes it very fast as compared to MapReduce.
Spark Ecosystem:
Spark Core: Spark Core is the main execution engine which manages the basic IO function, scheduling, monitoring etc. The entire spark ecosystem is built on top of this engine.
Spark SQL: Spark SQL is the module for structured data processing and acts as a distributed SQL query engine. Users can run complex SQL queries on their data at 100 times faster speed than in Hadoop.
Spark Streaming: This component helps developers in performing batch processing and streaming of data in an application. An example can be real time data streaming from twitter to analyze customer response in real time.
Spark MLib: The machine learning library enables development and deployment of scalable machine learning pipelines like summary statistics, correlation, feature extraction, transformation, optimization algorithms etc.
GraphX: This module allows data scientists to work with graph and non graph sources to achieve flexibility in graph construction and transformation.
Spark also supports programming languages like Scala, Python, R and Java. We can write the code in any of these programming languages and execute the program over Spark.

This are some of the popular solutions used widely in the industry today. Big data is a field where a lot of innovation is happening as we speak and many of the tools and solutions discussed above could become outdated in coming future. But these solutions define the way the platform has been built and what is the approach towards building better big data analytics solutions. Today, big data analytics is an essential component of any organization which wants to utilize petabytes of data that they have collected and turn it into quicker business insights. What today is niche, will become a hygiene factor tomorrow with the ever rise in computing power and newer solutions on the road.
