Containers are the new teenagers on the block. With the amount of flexibility in deployment and isolation from the underlying host it brings, containers are now being looked at seriously by many organizations. Many customers that I interact with, are now working on making their applications ‘cloud native’, and shifting workloads from the VM world to the container world. Many further, are ensuring that all new applications are designed and deployed to take the cloud native route from the very beginning. And when we talk about cloud native, containers become an important part of the conversation.
With a strong and now stable ecosystem setup around containerization technologies like docker; teams are now deploying production applications on containers in large numbers. Organizations moving towards cloud native setup are gravitating towards another important component apart from containers: Microservices. Applications are now being divided into smaller and sustainable units and deployed as such on containers, usually on a public cloud. With this practice, when we take a large application into production, we can imagine it to consist of multiple micro (or nano) services, all deployed on containers. This ends up leaving us with a large numbers of containers which we need to manage. When this numbers grows further to an unmanageable limit, there are some problems that come with it:
- Management of containers that need to communicate with each other in this large setup.
- Managing containers of the same application as a single family and implementing similar operations on them. Eg: IP address and ports set up for all the containers hosting the same application.
- Ensuring scaling for these containers as and when required.
- Distribution and load balancing of traffic across multiple containers which are catering to the same application.
There are many such issues that will pop up once you get neck deep with containers. The sheer volume of containers in an IT setup can bring a myriad of problems to the IT management team. And this is the part that needs to be automated. We need a container management system to step in and handle all the issues mentioned above and more. This is where we look at Kubernetes.
Kubernetes is an open source container management tool that automates container deployment, service discovery, container scaling and container load balancing.
Kubernetes was developed by Google and written in Golang. Google used kubernetes internally for more than a decade and finally launched it as an open source project in 2014, which is now managed by Cloud Native Computing Foundation (CNCF) which is the international open source body for cloud native technologies. Let’s look at the features of Kubernetes:
- Service Discovery and Load Balancing: Kubernetes automatically manages the networking component in containers. It enables inter-container communication and also provides a single IP address to a bunch of containers which are hosting the same application. Kubernetes also balances the load of traffic across all such containers.
- Storage Orchestration: Kubernetes allows you to mount storage setup of your choice on top on containers. You can mount local storage, cloud storage (cloud disks) or network storage (NAS) and manage them through Kubernetes.
- Self Healing: Kubernetes continuously monitors the health of containers and automatically restarts/ replaces the unhealthy containers to ensure that there are ‘n’ number of containers always available for the application.
- Secrets and Configuration Management: Kubernetes allows you to store the configuration and secrets (api keys, passwords etc) for an application separately in a secure manner. This way, the secrets and configuration can be updated and it will automatically apply to all the application containers that use it.
- Horizontal Scaling: Scaling up and down for containers is Kubernets is extremely easy and can be done with just one command on CLI or GUI. Kubernetes also enables auto scaling of containers for applications on the basis of several parameters that you might want to monitor.
- Automatic rollback and rollout: Kubernetes provides support for various deployment methodologies for newer versions. It supports Blue/Green deployment, rolling update, canary release, recreate and a/b testing. With this support, you have flexibility of rolling out new updates in a controlled manner and execute automatic rollback in case of any issue with the newer version.
Kubernetes Concepts
Nodes: Nodes are underlying machines on which various components of kubernetes will be deployed.
Master Node: Master Node is the orchestrator and manager of the entire kubernetes cluster. It manages a cluster of worker nodes and instructs them on various actions to be taken.
Worker Nodes: Worker nodes are nodes which have the actual application containers hosted in them. There are usually multiple worker nodes in a cluster. Worker nodes communicate with the master node and execute the commands given to them by the master.
Image Registry: This is the registry where we store containerized images of applications. These images are used to create containers in worker nodes.
Pods: The atomic unit of deployment in kubernetes. Pods are shells which contain one or more containers inside it.
Replication controller: It is a resource on master node which ensures that ‘n’ number of pods are always running for an application. It helps in maintaining the ‘desired state’ of the application.
Service: Service is an object that connects various pods to the network and also helps in balancing the load across the pods.
Kubernetes Architecture

Kubernetes Master Components
Kube API Server: The entire kubernetes cluster is exposed via API which is managed through Kube API Server. All the worker nodes as well as users interact with the API server which validates the requests and passes on the requests to appropriate component in the cluster. Users can communicate with API Server (and hence the cluster) through kubectl command line client or through REST API calls.
Etcd: Etcd is a distributed key value data store that stores the cluster metadata of the configuration. The entire cluster can be recreated using this data from etcd and hence etcd is also backed up for high availability and recovery. Any object or resource that is created in the cluster is stored in etcd.
Controller Manager: A controller is an entity that continuously monitors various objects and ensures that their current state matches the desired state. There are various controllers in kubernetes namely Daemonset controller, namespace controller, node lifecycle controller, deployment controller etc. The controller manager is the master controller for all these controllers. You can think of it as ‘controller of controllers’ or as ‘manager of controllers’.
Scheduler: Scheduler helps in scheduling pods across nodes. When a request is passed for creation of a pod, the scheduler will check resource requirement for the pod, the availability of such resources in nodes, if there are any instructions to launch the pod in a particular node or avoid a particular node. It checks all these details and then finally chooses where to schedule the pod.
Worker Node Components
Kubelet: kubelet runs on every node in the cluster. It manages all the pods in the cluster and constantly compares the current state vs desired state, and makes changes to ensure desired state is always maintained.
Kube-proxy: kube proxy is present in all the nodes and manages the networking of the nodes. Pods are able to communicate with the cluster through kube-proxy. It forwards the incoming request to the appropriate port of the pods and containers.
Container Runtime: A container runtime like docker, CRI-O is also present in all worker nodes and it helps in implementing containerization of applications to create containers.
Type of Kubernetes Clusters
Kubernetes can be deployed in various ways:
Single Node Cluster: Both master and worker are managed inside a single node. This is useful for small testing practices.
Single Master, multiple workers: In this architecture, there is a single master node which interacts with multiple worker nodes and manages the cluster.
Multiple Master, multiple workers: In order to achieve high availability for important workloads, we can also deploy multiple master nodes. In case the master node goes down, the secondary master node will step up and manage the cluster ensuring high availability.
Experiencing kubernetes in public cloud
Today, every major public cloud provides kubernetes service. The platform offers managed kubernetes service in which master node management and HA is taken care of by the platform and we have to work only with the worker nodes. This eases off a lot of management burden especially around taking care of master node and etcd. This also ensures that cluster can be created and managed with ease and is supported by helpful dashboards that give you an up-to-date picture of the running cluster.
In public cloud provider like Alibaba Cloud, there are various options when it comes to creating a kubernetes cluster. There are options of creating clusters with specific needs such as having a heterogeneous computing cluster, or a bare metal cluster, edge cluster or even a serverless cluster where the worker nodes are also managed by the platform making it extremely quick to get started with the cluster.
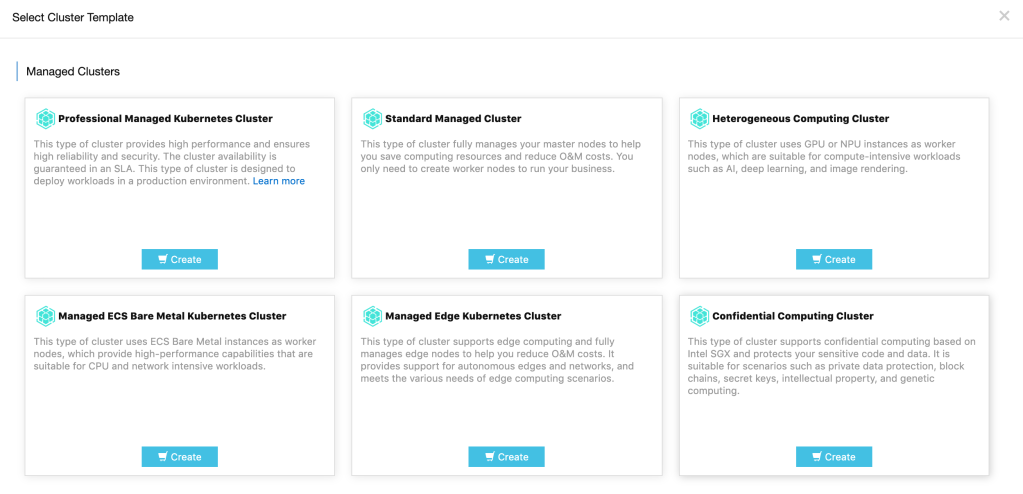
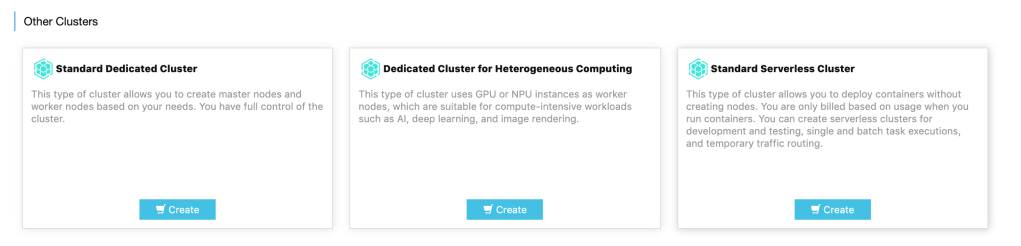
Once cluster is created, various dashboards give us precise picture of the cluster and makes management of the nodes very easy.


Similarly, managed kubernetes service is available in all major public cloud providers and it has become an integral part of the cloud native story for any organization. Kubernetes is setup for a bright future in the industry and organizations which get on the platform early will have a distinct advantage in turning up applications quickly, fostering a culture of learning and innovation and experiencing better cost management.
If you wish you dive deeper and learn kubernetes, I would recommend going through the book Kubernetes in Action by Marko Luksa.
