For a very long time, organizations have stored information about their applications in databases. This has worked well for decades. Storing information in database eventually forces us to think about information gathering as a subset of an object or a thing. A common example of this would be a ‘user’. We think of information gathering from a ‘user’ perspective and then store the ‘state’ relevant to this user(like his age, address etc) in the database. However, with the enormous amount of data being exchanged today between applications, the new wave of information gathering suggests thinking about ‘events‘ first, rather than objects/things first.
Events also have a state, which is an indication in time about what has happened, and this state is stored in a structure called log. This log is then accessed by various applications which post and consume information about events in real time. This is where the concept of event streaming comes, and comes with it – Apache Kafka.
Event streaming is capturing of data in real-time from event sources like databases, sensors, mobile devices, cloud services, and software applications in the form of streams of events; storing and processing these event streams in real-time and routing the event streams to different destination technologies as needed
How does Kafka work
Apache Kafka is an open source distributed event streaming platform that is used by organizations around the world to manage event streaming, and work as a communication layer for inter-communicating applications. Here, the events produced by applications are stored in log format and other applications can consume that data from the log as and when required. In absence of a solution like Kafka, organizations will have to connect applications to each other individually, and maintain that connection between these applications. A solution like Kafka becomes a common connection point between all the applications that need to communicate with each other. In order to understand the core concept of Apache Kafka, lets look at key terminology used in the solution:
Event: An event records the fact that “something happened” in the world or in your business. It is also known as message or data. Every event has a state, which is expressed in the form of key, value, timestamp, and other optional metadata.
Example:
Event Key: “Bob”
Event Value: “Made a payment of $100 to Kevin”
Event Timestamp: “21 March 2021, 1:26 PM”
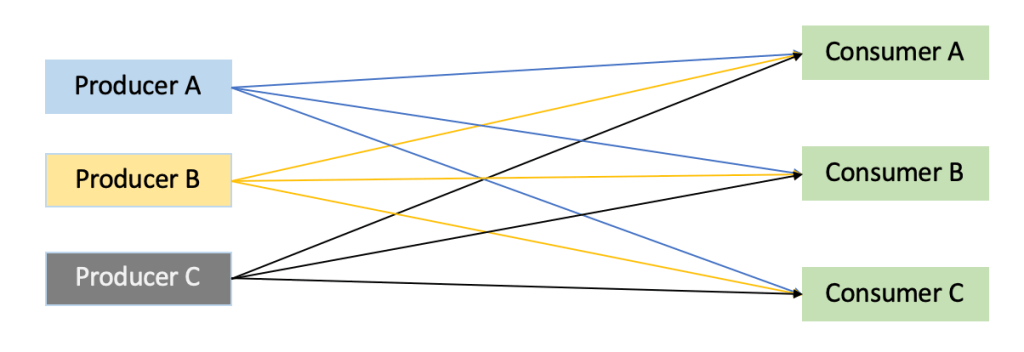
Producer: A producer is any application that sends data to Kafka. In the above example of Bob paying $100 to Kevin, the event was produced probably by the payment application which published the payment information and sent it to Kafka for storage and processing.
Consumer: A consumer is any application that reads data from Kafka. In the above example, the payment application sent payment data to Kafka and any application that is interested in this data can request Kafka to read it, given it has the permission to do so. The consumer application here could be a payment history database or another application that uses this event information.
Broker: Kafka servers are known as brokers, and rightly so, as consumer and producer applications do not interact with each other directly, but through Kafka servers which act as brokers in between.

Cluster: A Kafka cluster is a group of kafka brokers deployed together to enable benefits of distributed computing. Having multiple brokers ensure ability of the brokers to manage higher message load, and it also helps in ensuring fault tolerance in the broker architecture.
Zookeeper: Zookeeper, with regards to Kafka, is an application that works as a centralized service for managing the brokers and performing operations like maintaining configuration information, naming, providing distributed synchronization, and providing group services for Kafka brokers.

Topic: A topic is a unique name for a data stream that producer and consumer applications are using. Data published by producers is segmented into various topics (like Payment Data, Inventory Data, Customer Data etc), and consumer applications can subscribe to whichever topic they would like to access data from. More that one producers can publish data to a single topic, and more than one consumers can pull data from a single topic.
Partition: We have established that brokers store data streams in topics. The data stream can vary in size ranging from a few bits to a size more than that of storage of an individual broker also. Due to this, a data stream can be divided into smaller packets called partition. Kafka can divide a topic into partitions and spread it among different brokers in the cluster. Creating multiple partitions and storing in different brokers also help Kafka establish fault tolerance in the system.
Offset: Offset is a sequence ID that is given to the message as it arrives in the partition. This ID is unique inside the partition and helps setup an address for the message. If we want to access a message in Kafka, all we need to know is the Topic name, Partition number and the Offset.
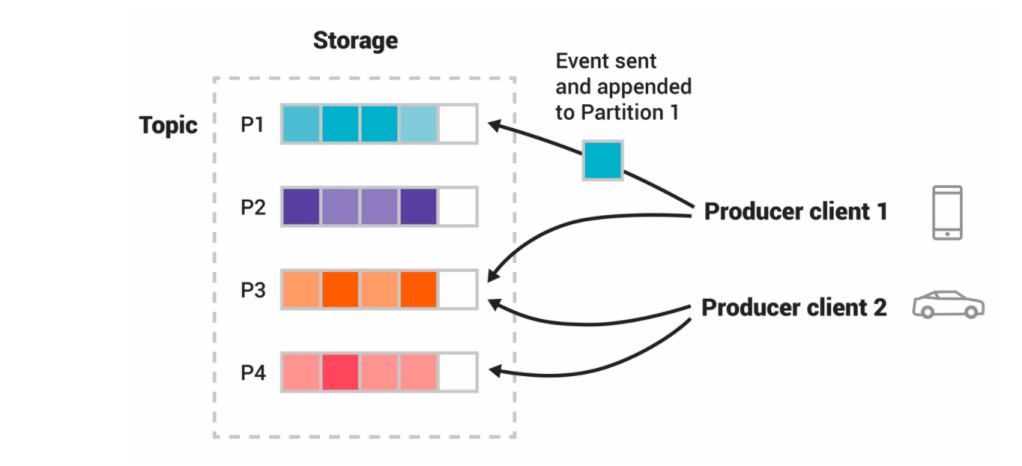
Source: kafka.apache.org
Consumer Group: This is a group of consumers that divide partitions among them in order to manage increasing workload coming from Kafka brokers. When there are hundreds of producer applications sending data to multiple brokers in Kafka, a single consumer can get overwhelmed with the velocity of incoming messages. Therefore, a group of consumers can be created, where partitions are assigned to these consumers to manage the consumption of data effectively.
Setup Kafka – Quick guide
Step 1: Download Kafka
You can download latest kafka release from the official website.
Once downloaded, extract the bits in your machine
$ tar -xzf kafka_2.13-2.7.0.tgz $ cd kafka_2.13-2.7.0
Step 2: Setup Kafka Environment
Start the Zookeeper service
$ bin/zookeeper-server-start.sh config/zookeeper.properties
Start Kafka Broker service (in a different terminal)
$ bin/kafka-server-start.sh config/server.properties

With Zookeeper and Kafka broker up and running, you have a Kafka environment ready for use.
Step 3: Create Topics
Before we can produce and consume messages, we must create a topic first. In a new terminal, create a topic:
$ bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
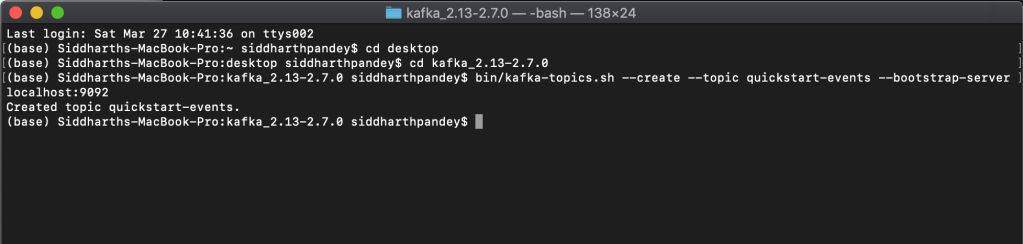
A topic has been created in your local machine accessible at port 9092 by using –create –topic command in kafka. You can also see details about the topic created by using the –describe command
$ bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092

You will see details about the topic such as partition count, replication factor etc.
Step 4: Write events into the topic
Now we can run a producer client and start writing messages in the topic. In a new terminal:
$ bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092

Start writing as many messages as you want with every new line representing a new message. To stop, press ctrl+c.
Step 5: Read events from the topic
With the events published from the producer, we can now run the consumer client and read those messages. In a new terminal:
$ bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092

You will now see the messages that were published by the producer. There you go! A quick implementation of Kafka service.
Step 6: Terminate the setup
- Stop consumer and producer clients by pressing ctrl+c. Close the terminal.
- Stop the Kafka broker with ctrl+c. Close the terminal.
- Finally, stop the zookeeper client with ctrl+c. Close the terminal. Take the rest of the day off.
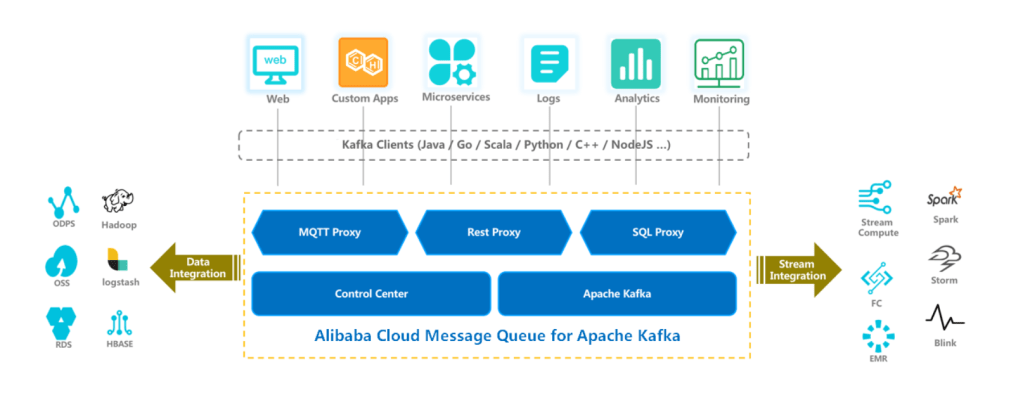
This is an easy way to set up kafka environment in your local machine and manage the topics. But in an enterprise scenario, where there are hundreds of producers, consumers and thousands of topics, it can get overwhelming to manage all the brokers and topics. This is where managed services on public cloud come handy. Kafka brokers are now hosted on cloud as a managed service. One such example in public cloud is Alibaba Message Queue for Apache Kafka.
Message Queue for Apache Kafka provides fully managed services for open source Apache Kafka, solving long-term shortcomings of open source Apache Kafka. Message Queue for Apache Kafka frees you from deployment and O&M. You can focus only on business development. Compared with open source Apache Kafka, Message Queue for Apache Kafka features lower costs, stronger scalability, and higher reliability.